監控(Monitoring)是橫跨多個世代確保系統穩定的維運技術,而 Metrics 就是其關注的焦點;同時 Metrics 也是 Observability 的重要基石。特別是在實踐 SRE(Site Reliability Engineering,網站可靠性工程)時,主要的概念如 SLI(Service-Level Indicator,服務水準指標)、SLO(Service-Level Objective,服務水準目標)以及 SLA(Service-Level Agreement,服務水準協議)都是以 Metrics 為核心。這些概念幫助我們定義什麼是重要的指標,這些指標需要達到什麼水準才算合格,以及如何對這些指標作出承諾。透過遵循這些概念,能讓我們確保系統的穩定性,並妥善地管理系統。

管理大師彼得杜拉克:「如果你不能衡量它,就不能管理它」
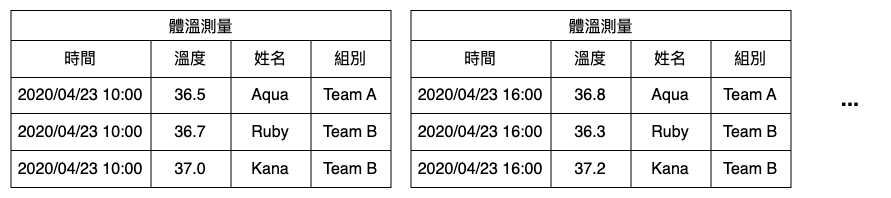
讓我們先來思考指標通常包含哪些要素。以體溫當作指標為例,在 2019 年 COVID-19 剛開始的初期,因為還沒有快篩,發燒成了一個重要的確診徵兆。家家戶戶都在量體溫,像我們公司內部也開始實施每日體溫測量,每個人的測量結果會紀錄在一張表上。首先,我們要測量的「體溫」就是指標的名稱;其次是測量到的「數值」;第三是測量的「時間」,因為一天內可能需要多次測量;最後是其他的「補充資訊」,例如被測量人的姓名、組別等。這樣一張張的表格組合起來,就可以獲得橫跨不同時間點的體溫數據。由於資料會根據時間不斷紀錄,這類資料被稱為時間序列資料(Time Series Data)。
通常,時間序列資料會存放在特別設計的時間序列資料庫(Time Series Database)中。相對於一般資料庫,這類資料庫是專為寫入和查詢優化,因為修改和異動的機會很少。另外,通常我們會想關注特定時間的狀況,即以時間區間作為篩選條件。因此,時間序列資料庫針對這些特性進行了優化,以提供更好的效能。
在本系列中,Metrics 主要皆以 Prometheus Metrics 為主進行討論。以下就他的四個處理階段進行說明:
生成
Prometheus Metrics 由四個部分構成:
應用程式可以透過 Prometheus Client Library 生成 Prometheus Metrics。有官方以及第三方的多種不同語言 Library,另外也有針對機器或服務設計的各種 Exporter 能夠自動採集資料轉換成 Prometheus Metrics。

Java Spring Boot Application 的 Prometheus Metrics
收集
從產生 Metrics 的服務角度來看,主要分為 Pull 與 Push 兩種模式:
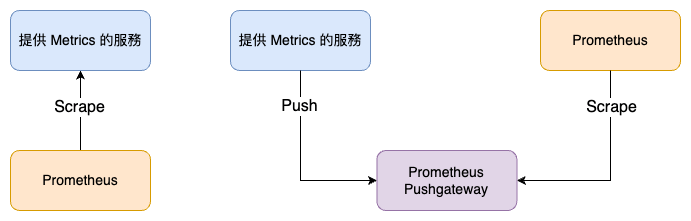
Prometheus Metrics 收集架構圖
儲存
Prometheus 預設會將資料儲存於本機磁碟的時間序列資料庫中。視資料的應用情境,若需要保存大量或長期的資料(例如超過千萬筆時間序列)時,官方建議搭配其他的儲存解決方案,例如接下來我們會介紹的 Mimir、Cortex、Thanos。
使用
儲存後的 Prometheus Metrics 可以使用專屬的 PromQL 語法查詢指標,或者搭配 Grafana 建立 Dashboard 以不同的視覺化方式檢視指標。
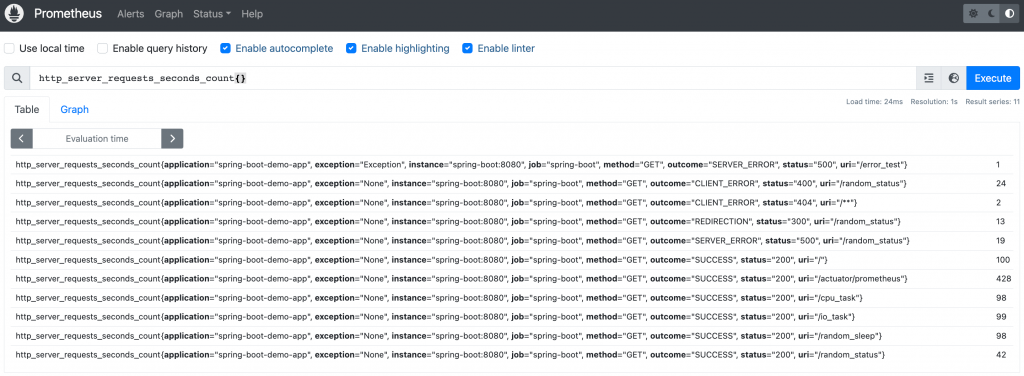
PromQL 查詢結果
以上即為 Metrics 的簡易介紹。接下來的章節將詳細介紹 Prometheus、Exporter、各種儲存解決方案,以及另外兩個也在 Metrics 領域深耕許久的 StatsD 和 Zabbix。
有人會問說metric的資料儲存要多久, 要多大? 會不會有暴增量的情況發生
metric data基本上都是落後指標, 一定要存放好幾個月來做事後分析甚至給機器學習用
要多大?因為metric data不求即時性通常能選擇像用Grafana Mimir存放在AWS S3, gcp GCS 做object storag, 沒那麼貴還不用擔心容量不夠
爆量問題, 中小規模的系統也不用擔心,
pull model拉到的都是當時拉的當下的量測資料點的快照而已, 預設15s拉一次, 一個metrics 一天也才5760筆樣本(可估算的), 資料大小也能高度壓縮
push的話, prometheus也是先推倒push gateway, prometheus才pull走.
除非有人白目在prometheus開remote write mode XD
我好像老人在亂入喇賽, 期待大大的後續內容
感謝大大的回饋分享,目前是還沒有經歷過單 Prometheus 資料爆量的情況,但有遇到 Prometheus 太多座,設計 Dashboard 時 Grafana Data Source 的配對實在太麻煩,所以就決定直接導單一的儲存服務,這樣只要對同一個地方 Query 就好,使用資料的末端的架構設計也會比較乾淨一點。
另外覺得有多一個專門的儲存服務算是實踐讀寫分離的一種方式吧?畢竟 Prometheus 還要負責去爬取資料,當要爬的 Host 跟 Metrics 數量一大起來,如果同時還要兼顧 Query,效能應該多少會互相影響?

